2024
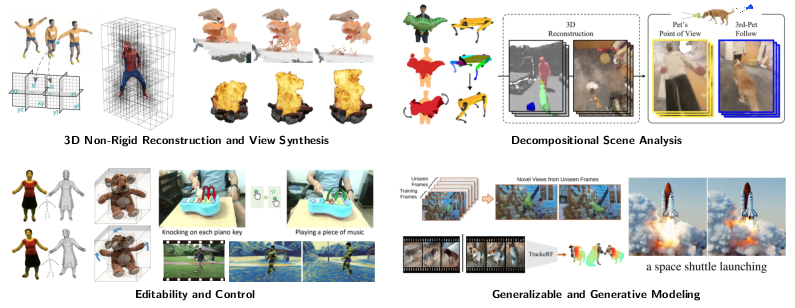
Recent Trends in 3D Reconstruction of General Non-Rigid Scenes
Raza Yunus, Jan Eric Lenssen, Michael Niemeyer, Yiyi Liao, Christian Rupprecht, Christian Theobalt, Gerard Pons-Moll, Jia-Bin Huang, Vladislav Golyanik, Eddy Ilg
Eurographics (STAR) and Computer Graphics Forum 2024
Reconstructing models of the real world, including 3D geometry, appearance, and motion of real scenes, is essential for computer graphics and computer vision. It enables the synthesizing of photorealistic novel views, useful for the movie industry and AR/VR applications. It also facilitates the content creation necessary in computer games and AR/VR by avoiding laborious manual design processes. Further, such models are fundamental for intelligent computing systems that need to interpret real-world scenes and actions to act and interact safely with the human world. Notably, the world surrounding us is dynamic, and reconstructing models of dynamic, non-rigidly moving scenes is a severely underconstrained and challenging problem. This state-of-the-art report (STAR) offers the reader a comprehensive summary of state-of-the-art techniques with monocular and multi-view inputs such as data from RGB and RGB-D sensors, among others, conveying an understanding of different approaches, their potential applications, and promising further research directions. The report covers 3D reconstruction of general non-rigid scenes and further addresses the techniques for scene decomposition, editing and controlling, and generalizable and generative modeling. More specifically, we first review the common and fundamental concepts necessary to understand and navigate the field and then discuss the state-of-the-art techniques by reviewing recent approaches that use traditional and machine-learning-based neural representations, including a discussion on the newly enabled applications. The STAR is concluded with a discussion of the remaining limitations and open challenges.
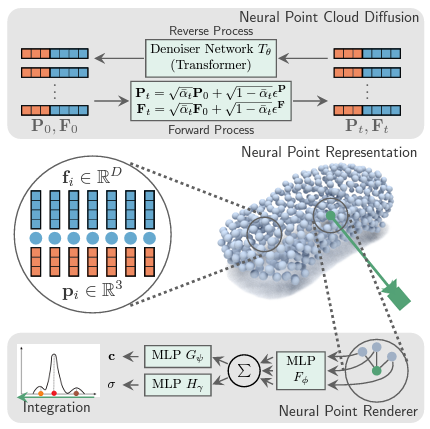
Neural Point Cloud Diffusion for Disentangled 3D Shape and Appearance Generation
Philipp Schröppel, Christopher Wewer, Jan Eric Lenssen, Eddy Ilg, Thomas Brox
Conference on Computer Vision and Pattern Recognition (CVPR) 2024
Controllable generation of 3D assets is important for many practical applications like content creation in movies, games and engineering, as well as in AR/VR. Recently, diffusion models have shown remarkable results in generation quality of 3D objects. However, none of the existing models enable disentangled generation to control the shape and appearance separately. For the first time, we present a suitable representation for 3D diffusion models to enable such disentanglement by introducing a hybrid point cloud and neural radiance field approach. We model a diffusion process over point positions jointly with a high-dimensional feature space for a local density and radiance decoder. While the point positions represent the coarse shape of the object, the point features allow modeling the geometry and appearance details. This disentanglement enables us to sample both independently and therefore to control both separately. Our approach sets a new state of the art in generation compared to previous disentanglement-capable methods by reduced FID scores of 30-90% and is on-par with other non disentanglement-capable state-of-the art methods.
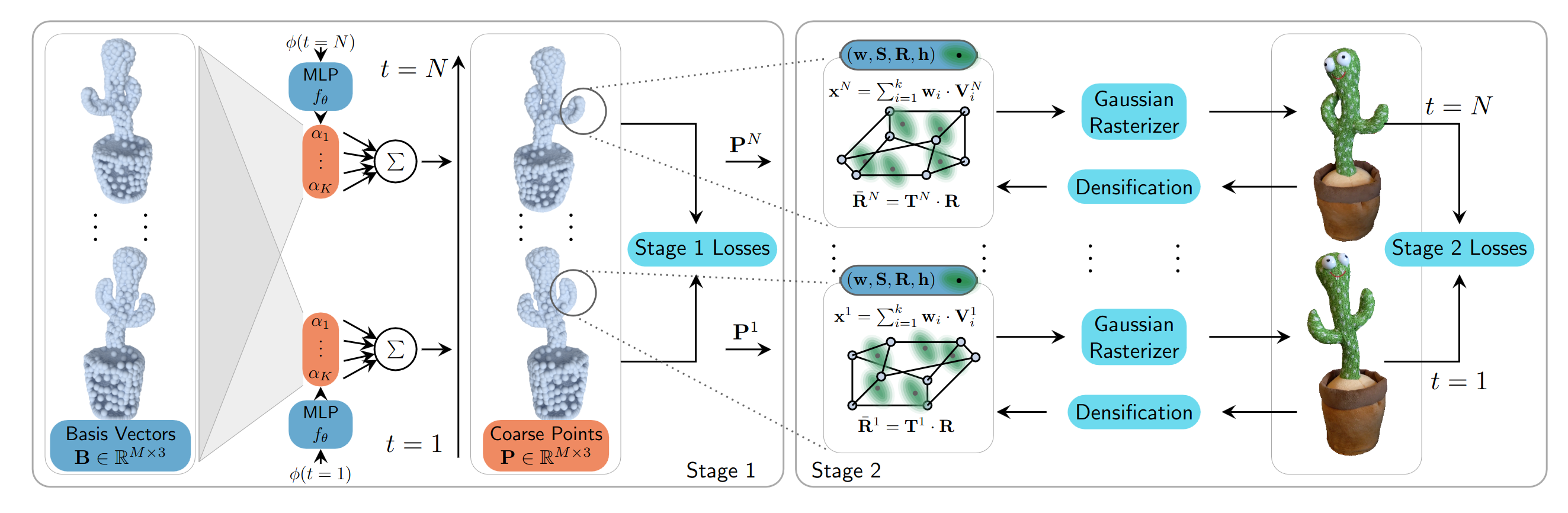
Neural Parametric Gaussians for Monocular Non-Rigid Object Reconstruction
Devikalyan Das, Christopher Wewer, Raza Yunus, Eddy Ilg, Jan Eric Lenssen
Conference on Computer Vision and Pattern Recognition (CVPR) 2024
Reconstructing dynamic objects from monocular videos is a severely underconstrained and challenging problem, and recent work has approached it in various directions. However, owing to the ill-posed nature of this problem, there has been no solution that can provide consistent, high-quality novel views from camera positions that are significantly different from the training views. In this work, we introduce Neural Parametric Gaussians (NPGs) to take on this challenge by imposing a two-stage approach: first, we fit a low-rank neural deformation model, which then is used as regularization for non-rigid reconstruction in the second stage. The first stage learns the object’s deformations such that it preserves consistency in novel views. The second stage obtains high reconstruction quality by optimizing 3D Gaussians that are driven by the coarse model. To this end, we introduce a local 3D Gaussian representation, where temporally shared Gaussians are anchored in and deformed by local oriented volumes. The resulting combined model can be rendered as radiance fields, resulting in high-quality photo-realistic reconstructions of the non-rigidly deforming objects, maintaining 3D consistency across novel views. We demonstrate that NPGs achieve superior results compared to previous works, especially in challenging scenarios with few multi-view cues.
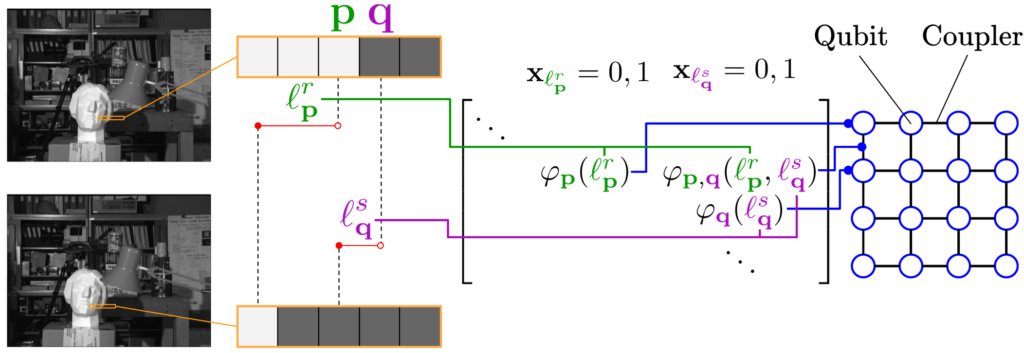
Quantum-Hybrid Stereo Matching With Nonlinear Regularization and Spatial Pyramids
Cameron Braunstein, Eddy Ilg, Vladislav Golyanik
International Conference on 3D Vision (3DV) 2024
Quantum visual computing is advancing rapidly. This paper presents a new formulation for stereo matching with nonlinear regularizers and spatial pyramids on quantum annealers as a maximum a posteriori inference problem that minimizes the energy of a Markov Random Field. Our approach is hybrid (i.e., quantum-classical) and is compatible with modern D-Wave quantum annealers, i.e., it includes a quadratic unconstrained binary optimization (QUBO) objective. Previous quantum annealing techniques for stereo matching are limited to using linear regularizers, and thus, they do not exploit the fundamental advantages of the quantum computing paradigm in solving combinatorial optimization problems. In contrast, our method utilizes the full potential of quantum annealing for stereo matching, as nonlinear regularizers create optimization problems which are NP-hard. On the Middlebury benchmark, we achieve an improved root mean squared accuracy over the previous state of the art in quantum stereo matching of 2% and 22.5% when using different solvers.
2023
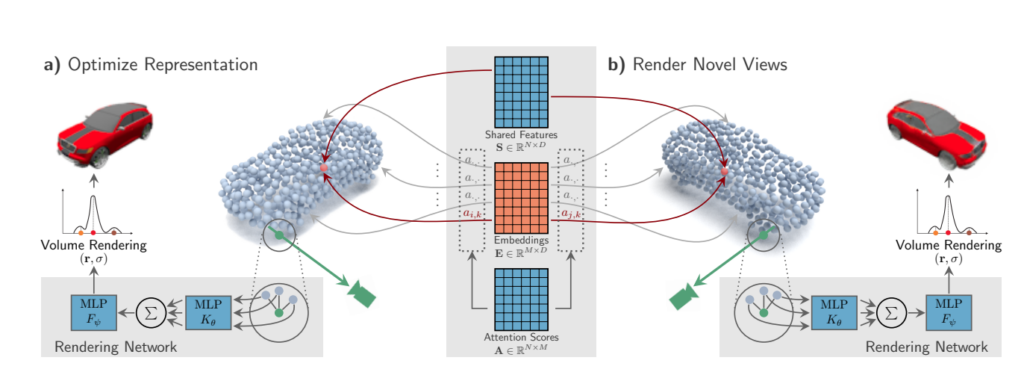
SimNP: Learning Self-Similarity Priors Between Neural Points
Christopher Wewer, Eddy Ilg, Bernt Schiele, Jan Eric Lenssen
International Conference on Computer Vision (ICCV) 2023
Existing neural field representations for 3D object reconstruction either (1) utilize object-level representations, but suffer from low-quality details due to conditioning on a global latent code, or (2) are able to perfectly reconstruct the observations, but fail to utilize object-level prior knowledge to infer unobserved regions. We present SimNP, a method to learn category-level self-similarities, which combines the advantages of both worlds by connecting neural point radiance fields with a category-level self-similarity representation. Our contribution is two-fold. (1) We design the first neural point representation on a category level by utilizing the concept of coherent point clouds. The resulting neural point radiance fields store a high level of detail for locally supported object regions. (2) We learn how information is shared between neural points in an unconstrained and unsupervised fashion, which allows to derive unobserved regions of an object during the reconstruction process from given observations. We show that SimNP is able to outperform previous methods in reconstructing symmetric unseen object regions, surpassing methods that build upon category-level or pixel-aligned radiance fields, while providing semantic correspondences between instances
2022
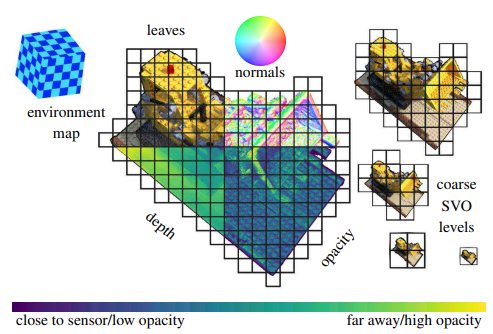
ERF: Explicit Radiance Field Reconstruction From Scratch
Samir Aroudj, Steven Lovegrove, Eddy Ilg, Tanner Schmidt, Michael Goesele and Richard Newcombe
arXiv Paper 2022
We propose a novel explicit dense 3D reconstruction approach that processes a set of images of a scene with sensor poses and calibrations and estimates a photo-real digital model. One of the key innovations is that the underlying volumetric representation is completely explicit in contrast to neural network-based (implicit) alternatives. We encode scenes explicitly using clear and understandable mappings of optimization variables to scene geometry and their outgoing surface radiance. We represent them using hierarchical volumetric fields stored in a sparse voxel octree. Robustly reconstructing such a volumetric scene model with millions of unknown variables from registered scene images only is a highly non-convex and complex optimization problem. To this end, we employ stochastic gradient descent (Adam) which is steered by an inverse differentiable renderer.
We demonstrate that our method can reconstruct models of high quality that are comparable to state-of-the-art implicit methods. Importantly, we do not use a sequential reconstruction pipeline where individual steps suffer from incomplete or unreliable information from previous stages, but start our optimizations from uniformed initial solutions with scene geometry and radiance that is far off from the ground truth. We show that our method is general and practical. It does not require a highly controlled lab setup for capturing but allows for reconstructing scenes with a vast variety of objects, including challenging ones, such as outdoor plants or furry toys. Finally, our reconstructed scene models are versatile thanks to their explicit design. They can be edited interactively which is computationally too costly for implicit alternatives.
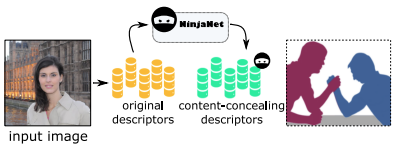
NinjaDesc: Content-Concealing Visual Descriptors via Adversarial Learning
Tony Ng, Hyo Jin Kim, Vincent Lee, Daniel DeTone, Tsun-Yi Yang, Tianwei Shen, Eddy Ilg, Vassileios Balntas, Krystian Mikolajczyk and Chris Sweeney
Conference on Computer Vision and Pattern Recognition (CVPR) 2022
In the light of recent analyses on privacy-concerning scene revelation from visual descriptors, we develop descriptors that conceal the input image content. In particular, we propose an adversarial learning framework for training visual descriptors that prevent image reconstruction, while maintaining the matching accuracy. We let a feature encoding network and image reconstruction network compete with each other, such that the feature encoder tries to impede the image reconstruction with its generated descriptors, while the reconstructor tries to recover the input image from the descriptors. The experimental results demonstrate that the visual descriptors obtained with our method significantly deteriorate the image reconstruction quality with minimal impact on correspondence matching and camera localization performance.
2021
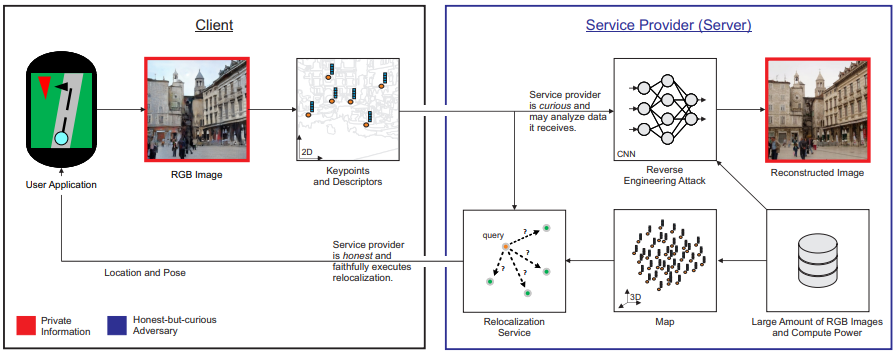
Mitigating Reverse Engineering Attacks on Local Feature Descriptors
Deeksha Dangwal, Vincent T. Lee, Hyo Jin Kim, Tianwei Shen, Meghan Cowan, Rajvi Shah, Caroline Trippel, Brandon Reagen, Timothy Sherwood, Vasileios Balntas, Armin Alaghi and Eddy Ilg
British Machine Vision Conference (BMVC) 2021
As autonomous driving and augmented reality evolve, a practical concern is data privacy. In particular, these applications rely on localization based on user images. The widely adopted technology uses local feature descriptors, which are derived from the images and it was long thought that they could not be reverted back. However, recent work has demonstrated that under certain conditions reverse engineering attacks are possible and allow an adversary to reconstruct RGB images. This poses a potential risk to user privacy. We take this a step further and model potential adversaries using a privacy threat model. Subsequently, we show under controlled conditions a reverse engineering attack on sparse feature maps and analyze the vulnerability of popular descriptors including FREAK, SIFT and SOSNet. Finally, we evaluate potential mitigation techniques that select a subset of descriptors to carefully balance privacy reconstruction risk while preserving image matching accuracy; our results show that similar accuracy can be obtained when revealing less information.
2020
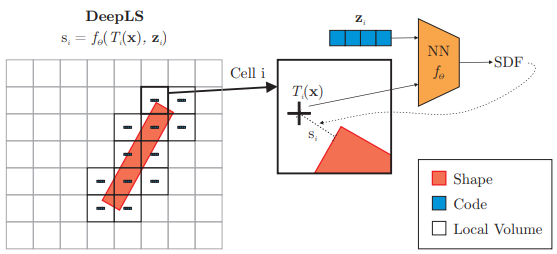
Deep Local Shapes: Learning Local SDF Priors for Detailed 3D Reconstruction
Rohan Chabra, Jan Eric Lenssen, Eddy Ilg, Tanner Schmidt, Julian Straub, Steven Lovegrove and Richard Newcombe
European Conference on Computer Vision (ECCV) 2020
Efficiently reconstructing complex and intricate surfaces at scale is a long-standing goal in machine perception. To address this problem we introduce Deep Local Shapes (DeepLS), a deep shape representation that enables encoding and reconstruction of high-quality 3D shapes without prohibitive memory requirements. DeepLS replaces the dense volumetric signed distance function (SDF) representation used in traditional surface reconstruction systems with a set of locally learned continuous SDFs defined by a neural network, inspired by recent work such as DeepSDF. Unlike DeepSDF, which represents an object-level SDF with a neural network and a single latent code, we store a grid of independent latent codes, each responsible for storing information about surfaces in a small local neighborhood. This decomposition of scenes into local shapes simplifies the prior distribution that the network must learn, and also enables efficient inference. We demonstrate the effectiveness and generalization power of DeepLS by showing object shape encoding and reconstructions of full scenes, where DeepLS delivers high compression, accuracy, and local shape completion.
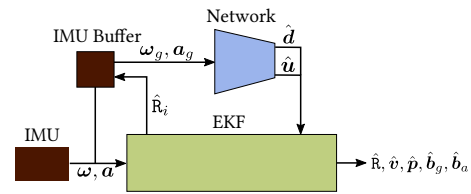
TLIO: Tight Learned Inertial Odometry
Wenxin Liu, David Caruso, Eddy Ilg, Jing Dong, Anastasios I. Mourikis, Kostas Daniilidis, Vijay Kumar and Jakob Engel
IEEE Robotics and Automation Letters 2020
In this work, we propose a tightly-coupled Extended Kalman Filter framework for IMU-only state estimation. Strap-down IMU measurements provide relative state estimates based on IMU kinematic motion model. However the integration of measurements is sensitive to sensor bias and noise, causing significant drift within seconds. Recent research by Yan et al. (RoNIN) and Chen et al. (IONet) showed the capability of using trained neural networks to obtain accurate 2D displacement estimates from segments of IMU data and obtained good position estimates from concatenating them. This paper demonstrates a network that regresses 3D displacement estimates and its uncertainty, giving us the ability to tightly fuse the relative state measurement into a stochastic cloning EKF to solve for pose, velocity and sensor biases. We show that our network, trained with pedestrian data from a headset, can produce statistically consistent measurement and uncertainty to be used as the update step in the filter, and the tightly-coupled system outperforms velocity integration approaches in position estimates, and AHRS attitude filter in orientation estimates.
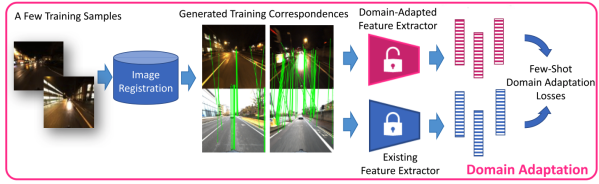
Domain Adaptation of Learned Features for Visual Localization
Sungyong Baik, Hyo Jin Kim, Tianwei Shen, Eddy Ilg, Kyoung Mu Lee and Christopher Sweeney
British Machine Vision Conference (BMVC) 2020
We tackle the problem of visual localization under changing conditions, such as time of day, weather, and seasons. Recent learned local features based on deep neural networks have shown superior performance over classical hand-crafted local features. However, in a real-world scenario, there often exists a large domain gap between training and target images, which can significantly degrade the localization accuracy. While existing methods utilize a large amount of data to tackle the problem, we present a novel and practical approach, where only a few examples are needed to reduce the domain gap. In particular, we propose a few-shot domain adaptation framework for learned local features that deals with varying conditions in visual localization. The experimental results demonstrate the superior performance over baselines, while using a scarce number of training examples from the target domain.
2019
Overcoming Limitations of Mixture Density Networks: A Sampling and Fitting Framework for Multimodal Future Prediction
Osama Makansi, Eddy Ilg, Özgün Çiçek and Thomas Brox
Conference on Computer Vision and Pattern Recognition (CVPR) 2019
Future prediction is a fundamental principle of intelligence that helps plan actions and avoid possible dangers. As the future is uncertain to a large extent, modeling the uncertainty and multimodality of the future states is of great relevance. Existing approaches are rather limited in this regard and mostly yield a single hypothesis of the future or, at the best, strongly constrained mixture components that suffer from instabilities in training and mode collapse. In this work, we present an approach that involves the prediction of several samples of the future with a winner-takes-all loss and iterative grouping of samples to multiple modes. Moreover, we discuss how to evaluate predicted multimodal distributions, including the common real scenario, where only a single sample from the ground-truth distribution is available for evaluation. We show on synthetic and real data that the proposed approach triggers good estimates of multimodal distributions and avoids mode collapse.
2018

What Makes Good Synthetic Training Data for Learning Disparity and Optical Flow Estimation?
Nikolaus Mayer, Eddy Ilg, Philipp Fischer, Caner Hazirbas, Daniel Cremers, Alexey Dosovitskiy and Thomas Brox
Int. Journal of Computer Vision (IJCV) 2018
The finding that very large networks can be trained efficiently and reliably has led to a paradigm shift in computer vision from engineered solutions to learning formulations. As a result, the research challenge shifts from devising algorithms to creating suitable and abundant training data for supervised learning. How to efficiently create such training data? The dominant data acquisition method in visual recognition is based on web data and manual annotation. Yet, for many computer vision problems, such as stereo or optical flow estimation, this approach is not feasible because humans cannot manually enter a pixel-accurate flow field. In this paper, we promote the use of synthetically generated data for the purpose of training deep networks on such tasks.We suggest multiple ways to generate such data and evaluate the influence of dataset properties on the performance and generalization properties of the resulting networks. We also demonstrate the benefit of learning schedules that use different types of data at selected stages of the training process.
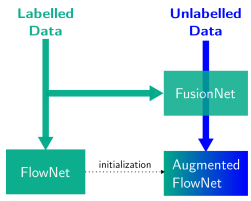
FusionNet and AugmentedFlowNet: Selective Proxy Ground Truth for Training on Unlabeled Images
Osama Makansi, Eddy Ilg and Thomas Brox
arXiv Paper 2018
Recent work has shown that convolutional neural networks (CNNs) can be used to estimate optical flow with high quality and fast runtime. This makes them preferable for real-world applications. However, such networks require very large training datasets. Engineering the training data is difficult and/or laborious. This paper shows how to augment a network trained on an existing synthetic dataset with large amounts of additional unlabelled data. In particular, we introduce a selection mechanism to assemble from multiple estimates a joint optical flow field, which outperforms that of all input methods. The latter can be used as proxy-ground-truth to train a network on real-world data and to adapt it to specific domains of interest. Our experimental results show that the performance of networks improves considerably, both, in cross-domain and in domain-specific scenarios. As a consequence, we obtain state-of-the-art results on the KITTI benchmarks.
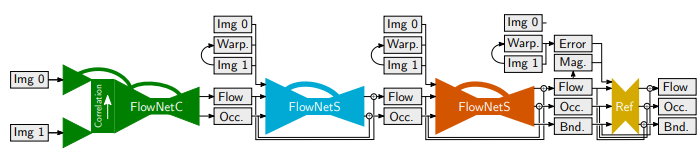
Occlusions, Motion and Depth Boundaries with a Generic Network for Disparity, Optical Flow or Scene Flow Estimation
Eddy Ilg, Tonmoy Saikia, Margret Keuper and Thomas Brox
European Conference on Computer Vision (ECCV) 2018
Occlusions play an important role in optical flow and disparity estimation, since matching costs are not available in occluded areas and occlusions indicate motion boundaries. Moreover, occlusions are relevant for motion segmentation and scene flow estimation. In this paper, we present an efficient learning-based approach to estimate occlusion areas jointly with optical flow or disparities. The estimated occlusions and motion boundaries clearly improve over the state of the art. Moreover, we present networks with state-of-the-art performance on the popular KITTI benchmark and good generic performance. Making use of the estimated occlusions, we also show improved results on motion segmentation and scene flow estimation.

Uncertainty Estimates and Multi-Hypotheses Networks for Optical Flow
Eddy Ilg, Özgün Çiçek, Silvio Galesso, Aaron Klein, Osama Makansi, Frank Hutter and Thomas Brox
European Conference on Computer Vision (ECCV) 2018
Optical flow estimation can be formulated as an end-to-end supervised learning problem, which yields estimates with a superior accuracy-runtime tradeoff compared to alternative methodology. In this paper, we make such networks estimate their local uncertainty about the correctness of their prediction, which is vital information when building decisions on top of the estimations. For the first time we compare several strategies and techniques to estimate uncertainty in a large-scale computer vision task like optical flow estimation. Moreover, we introduce a new network architecture and loss function that enforce complementary hypotheses and provide uncertainty estimates efficiently with a single forward pass and without the need for sampling or ensembles. We demonstrate the quality of the uncertainty estimates, which is clearly above previous confidence measures on optical flow and allows for interactive frame rates.
2017
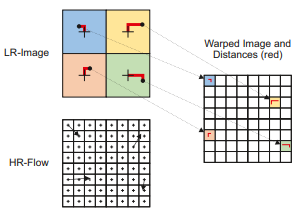
End-to-End Learning of Video Super-Resolution with Motion Compensation
Osama Makansi, Eddy Ilg and Thomas Brox
German Conference on Pattern Recognition (GCPR) 2017
Learning approaches have shown great success in the task of super-resolving an image given a low resolution input. Video superresolution aims for exploiting additionally the information from multiple images. Typically, the images are related via optical flow and consecutive image warping. In this paper, we provide an end-to-end video superresolution network that, in contrast to previous works, includes the estimation of optical flow in the overall network architecture. We analyze the usage of optical flow for video super-resolution and find that common off-the-shelf image warping does not allow video super-resolution to benefit much from optical flow. We rather propose an operation for motion compensation that performs warping from low to high resolution directly. We show that with this network configuration, video superresolution can benefit from optical flow and we obtain state-of-the-art results on the popular test sets. We also show that the processing of whole images rather than independent patches is responsible for a large increase in accuracy.
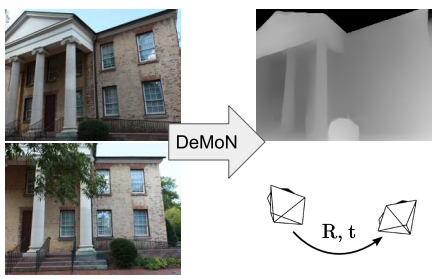
DeMoN: Depth and Motion Network for Learning Monocular Stereo
Benjamin Ummenhofer, Huizhong Zhou, Jonas Uhrig, Nikolaus Mayer, Eddy Ilg, Alexey Dosovitskiy and Thomas Brox
Conference on Computer Vision and Pattern Recognition (CVPR) 2017
In this paper, we formulate the structure from motion as a learning problem. We train a convolutional network end-to-end to compute depth and camera motion from successive, unconstrained image pairs. The architecture is composed of multiple stacked encoder-decoder networks, the core part being an iterative network that is able to improve its own predictions. The network estimates not only depth and motion but additionally surface normals, optical flow between the images, and confidence of the matching. A crucial component of the approach is a training loss based on spatial relative differences. Compared to traditional two-frame structures from motion methods, results are more accurate and robust. In contrast to the popular depth-from-single-image networks, DeMoN learns the concept of matching and, thus, better generalizes to structures not seen during training.
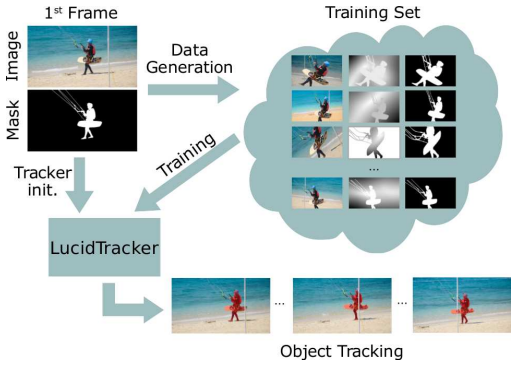
Lucid Data Dreaming for Object Tracking
Anna Khoreva, Rodrigo Benenson, Eddy Ilg, Thomas Brox and Bernt Schiele
Conference on Computer Vision and Pattern Recognition Workshop (CVPRW) 2017
Convolutional networks reach top quality in pixel-level object tracking but require a large amount of training data (1k to 10k) to deliver such results. We propose a new training strategy that achieves state-of-the-art results across three evaluation datasets while using 20 to 100 less annotated data than competing methods. Our approach is suitable for both for single and multiple-object tracking. Instead of using large training sets hoping to generalize across domains, we generate in-domain training data using the provided annotation on the first frame of each video to synthesize (“lucid dream”1 ) plausible future video frames. In-domain per-video training data allows us to train high-quality appearance- and motion-based models, as well as tune the post-processing stage. This approach allows to reach competitive results even when training from only a single annotated frame, without ImageNet pre-training. Our results indicate that using a larger training set is not automatically better and that for the tracking task a smaller training set that is closer to the target domain is more effective. This changes the mindset regarding how many training samples and general “objectness” knowledge are required for the object tracking task.

FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks
Eddy Ilg, Nikolaus Mayer, Tonmoy Saikia, Margret Keuper, Alexey Dosovitskiy and Thomas Brox
Conference on Computer Vision and Pattern Recognition (CVPR) 2017
The FlowNet demonstrated that optical flow estimation can be cast as a learning problem. However, the state of the art with regard to the quality of the flow has still been defined by traditional methods. Particularly on small displacements and real-world data, FlowNet cannot compete with variational methods. In this paper, we advance the concept of end-to-end learning of optical flow and make it work really well. The large improvements in quality and speed are caused by three major contributions: first, we focus on the training data and show that the schedule of presenting data during training is very important. Second, we develop a stacked architecture that includes warping of the second image with intermediate optical flow. Third, we elaborate on small displacements by introducing a subnetwork specializing on small motions. FlowNet 2.0 is only marginally slower than the original FlowNet but decreases the estimation error by more than 50%. It performs on par with state-of-the-art methods, while running at interactive frame rates. Moreover, we present faster variants that allow optical flow computation at up to 140fps with accuracy matching the original FlowNet.
2016

A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation
Nikolaus Mayer, Eddy Ilg, Philip Hausser, Philipp Fischer, Daniel Cremers, Alexey Dosovitskiy and Thomas Brox
Conference on Computer Vision and Pattern Recognition (CVPR) 2016
Recent work has shown that optical flow estimation can be formulated as a supervised learning task and can be successfully solved with convolutional networks. Training of the so-called FlowNet was enabled by a large synthetically generated dataset. The present paper extends the concept of optical flow estimation via convolutional networks to disparity and scene flow estimation. To this end, we propose three synthetic stereo video datasets with sufficient realism, variation, and size to successfully train large networks. Our datasets are the first large-scale datasets to enable the training and evaluation of scene flow methods. Besides the datasets, we present a convolutional network for real-time disparity estimation that provides state-of-the-art results. By combining a flow and disparity estimation network and training it jointly, we demonstrate the first scene flow estimation with a convolutional network.
2015
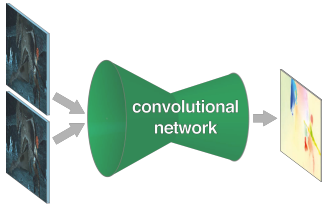
FlowNet: Learning Optical Flow with Convolutional Networks
Alexey Dosovitskiy, Philipp Fischer, Eddy Ilg, Philip Hausser, Caner Hazirbas, Vladimir Golkov, Patrick Van Der Smagt, Daniel Cremers and Thomas Brox
Int. Conference on Computer Vision (ICCV) 2015
Convolutional neural networks (CNNs) have recently been very successful in a variety of computer vision tasks, especially those linked to recognition. Optical flow estimation has not been among the tasks CNN’s succeeded at. In this paper, we construct CNNs that are capable of solving the optical flow estimation problem as a supervised learning task. We propose and compare two architectures: a generic architecture and another one including a layer that correlates feature vectors at different image locations. Since existing ground truth data sets are not sufficiently large to train a CNN, we generate a large synthetic Flying Chairs dataset. We show that networks trained on this unrealistic data still generalize very well to existing datasets such as Sintel and KITTI, achieving competitive accuracy at frame rates of 5 to 10 fps.
2014
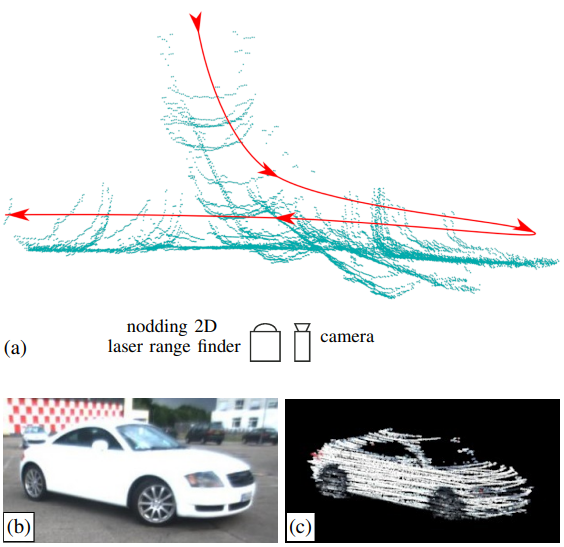
Reconstruction of Rigid Body Models from Motion Distorted Laser Range Data Using Optical Flow
Eddy Ilg, Rainer Kuemmerle, Wolfram Burgard, Thomas Brox
Int. Conference on Robotics and Automation (ICRA) 2014
The setup of tilting a 2D laser range finder up and down is a widespread strategy to acquire 3D point clouds. This setup requires that the scene is static while the robot takes a 3D scan. If an object moves through the scene during the measurement process and one does not take into account these movements, the resulting model will get distorted. This paper presents an approach to reconstruct the 3D model of a moving rigid object from the inconsistent set of 2D measurements by the help of a camera. Our approach utilizes optical flow in the camera images to estimate the motion in the image plane and point-line constraints to compensate the missing information about the motion in depth. We combine multiple sweeps and/or views into to a single consistent model using a point-to-plane ICP approach and optimize single sweeps by smoothing the resulting trajectory. Experiments obtained in real outdoor scenarios with moving cars demonstrate that our approach yields accurate models.